HCC2 Architecture
This section contains HCC2 architecture information that is relevant to SDK development. It provides greater detail than the user manual in the external references.
Because the HCC2 is a embedded system which is both a industrial control device and an application platform, design patterns and assumptions from the information technology (IT) and operational technology (OT) domains can overlap. As a result, developing software specifically for an 'industrial computer' or an 'RTU' can lead to missed opportunities, operational challenges for end users, or even security risks and production loss. This section provides context for developers to understand the way the HCC2 attempts to bridge the gap.
To leverage the full capabilities of the HCC2, read this section for insights on important concepts and the rationale behind them; in particular, those related to data points and configuration.
Important concepts are highlighted in block quotes.
System Architecture Overview
The HCC2 combines problem-solving capabilities for multiple domains. This design requires a balance of application portability, flexibility/configurability, and ease of use - a balance made possible by architecture and software development rules.
For example, a device may run a general purpose application that needs inputs from site-specific sources such as wellhead pressure. On one site, this measurement may be available via Modbus; and on another site, via a 4-20mA analog loop. To avoid modifying or recompiling the application for each installation, data points provide the necessary abstraction between the IO and the application. The process of mapping IO to data points and defining the settings for applications is called configuration.
An explanation of all internal elements within the HCC2 is beyond the scope of this document, but this diagram shows where an SDK application exists in the system.
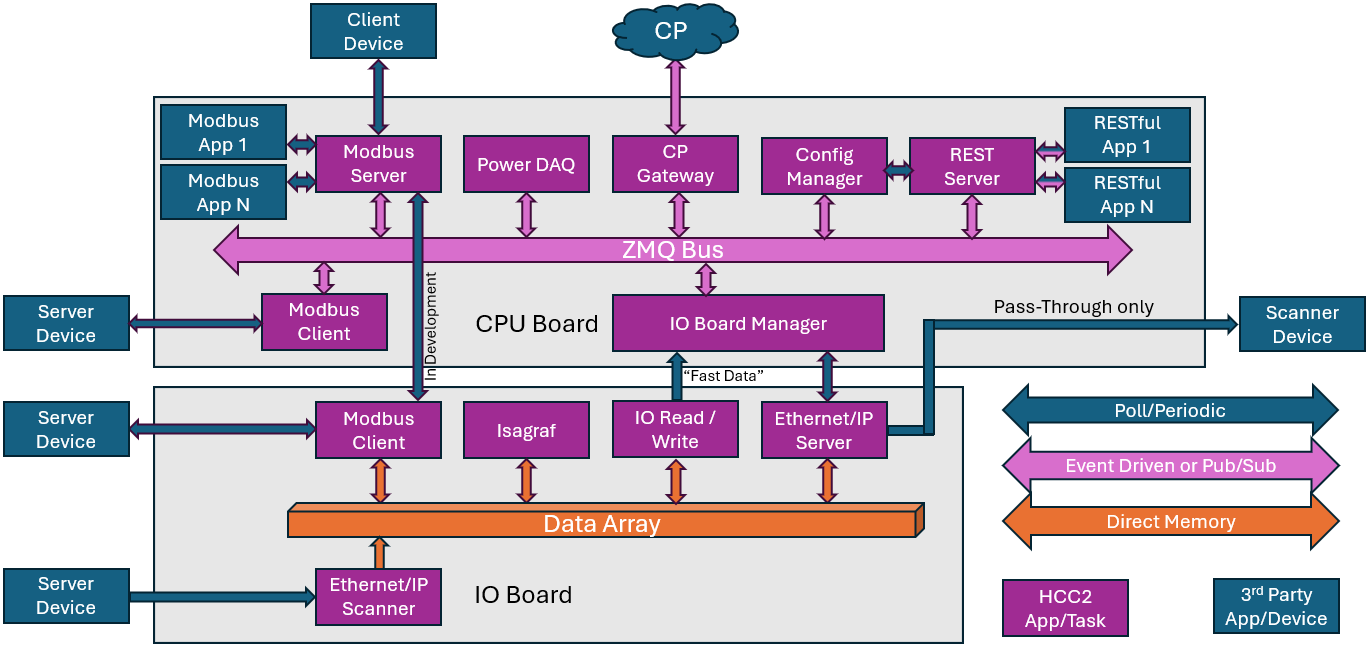
The following sections provide greater detail of these critical concepts as well as the related software and hardware systems that you will interact with in developing applications.
Physical System Architecture
The HCC2 hardware comprises two main components, the IO board and the CPU board.
The IO board manages analog and digital IO, two network interfaces, and some serial interfaces. A real time processor manages this IO and executes a ISaGRAF PLC environment.
The CPU board contains a much more powerful application processor and additional communication interfaces. HCC2 users can create logic targeting either environment, as PLC logic or a docker container respectively.
The HCC2 provides mechanisms for seamless communication between these very different environments using the software architecture and data structures described in the following sections. This ability to implement solutions blending time sensitive control behaviour with complex interpretation and event based behavior in an appropriate runtime environment for each on a single device is the foundation of the "hyperconverged" HCC2.
This separation of physical controls and development environments not only allows a choice of environment to optimize performance and software ecosystem, but helps segregate the high and low level control logic. It provides software/process security benefits and makes it possible to perform security updates or add features to the CPU board without interrupting the process being controlled by the IO board. To leverage this capability, developers and users must consider where data and control logic reside.
The CPU board's software and configuration can be updated without interrupting control on the IO board if the required process signals are local to the IO board and software and configuration of the IO board are not modified by the update.

Software Architecture
This section provides a high level overview of the software platform and the guiding principles behind application development for the HCC2.
Software Platform
The software platform within the IO board is focused on predictable real-time processing and includes the ISaGRAF environment where custom PLC style logic can be implemented.
The CPU board runs a stripped down Linux distribution and uses Docker to enable software to be added to the system. This host Linux OS resides in a read only root filesystem to enhance security, prevent flash wear, and ensure devices are in a consistent state with each OS update. Temporary File System (tempfs) mounts, overlays and a writable data partition enable the OS to operate normally and persist files within the data partition. This way, the capabilities of the OS are limited to update management, running docker containers via docker-compose, and providing interfaces to containers for system management such as network/firewall configuration. This design approach prevents installation of custom software or packages directly on the HCC2 host OS.
Most capabilities implemented in the HCC2 CPU board are done via Docker containers. Within the Host OS, the Docker containers, volumes, and OS configuration files reside within a writable data partition. Containers generally interact with the underlying OS as needed via bind mounts and security settings in their docker compose file, and do not interact directly with the OS.
Access to the underlying host OS in the HCC2 is limited. HCC2 capabilities are extended through applications residing within docker containers on the CPU board or within ISaGRAF on the IO board.
Software Updates
Details not covered in the user manual are included here to familiarize developers with software packaging processes as described in the Image Creation section. All software updates for the HCC2 are distributed as mender packages, and come in two main types, OS updates and container updates. Container updates contain the docker compose file(s) for the containers to run and either a full export of the container layers or the details of the hosted container registry where the containers can be pulled. The update files can be applied locally via the Sensia Edge Package Manager (EPM) software or online via mender.io (hosted or on-prem). The firmware of the IO board is updated by the IO Board Manager application on the CPU board. Therefore, an update to this software can trigger an update of the IO board firmware.
Guiding principles
The software architecture within the HCC2 reflects a intent to balance of many design goals important for a device capable of filling different niches in the edge compute and control space.
It ensures:
- New software and capabilities can be added, while maintaining a single, consistent end user experience for configuring and deploying the device.
- Data can be produced or consumed by any software in the system, while maintaining high performance.
- Layered security without undermining usability of the system.
- Both offline/local and online/remote configuration and device management.
- Seamless interaction between general purpose "apps" and fully custom site specific logic
- Regular software updates with minimal impact to operations
An important goal of the HCC2 is to allow users with limited software expertise to independently install an application on a fleet of devices with no additional custom control system or software development (code, UI etc.) with minimum site-specific configuration. This shifts some burden to developers, such as ensuring consistent naming of software inputs and outputs. This has the greatest impact as more applications are installed and more IO data points require interpretation. For example, imagine an upstream wellpad with software for production optimization, drive control, and valve health installed plus a service performing data collection to push to the cloud. If each of these applications require wellhead pressure as a input, our approach does not require you to configure each piece of software to know where the wellhead pressure is coming from (an analog input, HART, or Modbus for example). Ideally, the end user has one configuration operation, to assign analog input 1 to the wellhead pressure datapoint and all applications start consuming the required data. If, on another wellsite, the same software packages are installed, but the pressure is read via Modbus, then there is only one configuration difference between the two systems.
To achieve these goals, the methods used to configure the applications and to ensure communications with one another at runtime must be consistent.
Each application has a configuration phase prior to interacting with the data points defined in the system.
The sub sections below describe these concepts in more detail.
Key concepts for application development
Data Points
A Data Point is the smallest piece of information exchanged between applications within the HCC2. A data point has a number of properties that must be defined, including a name that complies with specified naming conventions. The other metadata, such as data type, unit of measure, and input/output identification ensure the contents are agreed upon by the sender and all receivers and there are no duplicate data points.
Every time a data point is updated, its value, quality code, and timestamp are updated simultaneously. This ensures the receiver has the necessary context for every update.
- Value: the new process value, matching the data type and defined unit of measure for the data point
- Quality: an applicable OPC quality code
- Timestamp: an integer number of microseconds since the Linux Epoch. (UTC timezone)
Values within the HCC2 are always sent in SI base units. This ensures all software exchanging data within the HCC2 only has to deal with one unit of measure. Software transmitting data in/out of the HCC2 (user screens, industrial protocol drivers, analog IO etc.) must be capable of converting to/from SI base units.
The HCC2 exchanges all time values in the UTC time zone. Time values are, converted to local time zones only when displaying localized time values for users.
During Configuration, all of the metadata for a datapoint is accessible to the rest of the system. Making this information available at configuration time ensures all software has the context it requires, eliminating the need to send each property of each datapoint every time the process value it represents is updated.
Data points belong to either of two main categories - general and configuration.
Each part of a data point's name helps specify its contents. This structure helps apps receive each update to the data points it needs as input without having to receive and filter data that is not of interest. See the Messages section for more details on subscriptions.
See the page on data point naming for important details on HCC2 naming conventions.
Configuration Data Points
Configuration data points have additional properties and behavior beyond those of general data points. Configuration data points typically have validation rules which restrict the values they can accept. These can be simple range checks or complex functions. If a configuration datapoint is defined with the property "No Protobuf" set to true, its value can only be changed when using the 'deploy' workflow in Unity Edge. If the "No Protobuf" property is set to false, it can be modified at runtime by any other app by updating the data point under the prevalidConfig subclass. The configuration manager observes any updates to prevalidConfig data points, and then validates them based on the above validation rules. If the validation passes, it is stored in non-volatile memory and re-published by the configuration manager on the postvalidConfig datapoint with a "good" quality code. If the validation fails, it is not stored and a message is published on the posvalidConfig data point indicating a "bad" quality code. It is the responsibility of the consuming application to check the quality code of any updated datapoint value.
Messages
Within the HCC2, every data point value change is distributed as a message from the publisher of the update to all subscribers using the ZeroMQ (ZMQ) asynchronous messaging library. Compared to a system where a central memory structure or database is queried, this has a number of advantages:
- High performance
- No contention over access
- No time wasted polling values which have not changed Responsive
- Updates are distributed to all subscribers the moment they occur
- Flexible
- Publishers and subscribers are not directly aware of each other, only the messages they are interested in
- Efficient when dealing with non-polling systems
- Protocols such as Modbus only need to poll the external device once and the result is distributed to all apps
- Easy to use
- Routing of data is simple, if a service needs a datapoint as a source, it subscribes to it.
- Users/operators only need to configure the source to publish the data without considering routing for all consumers
There are a few possible downsides to be aware of:
- No rate limit
- Subscribers cannot control the frequency of updates received
- Late joiner problem
- If you join late, you don't know the current value of a data point (this is mitigated with the last value cache)
- Event based paradigm
- Software needs to either be written in an event-based style, or added using a caching layer if it must perform its calculations on a fixed interval.
The SDK provides a window into this message bus.
Using the REST API, the default interaction is to poll a copy of the most recent message for a given datapoint from the REST server. This is a convenient option for simple applications or applications that perform a calculations on a slow, fixed interval. Use webhooks to receive updates on change, allowing apps to use the underlying message bus within the HCC2.
Complex Messages
Sometimes multiple simple data points must be transmitted as an atomic unit. For example, if the GPS within the HCC2 were to transmit the latitude and longitude values in separate messages, it would be difficult to know your current position. You would receive one half of the coordinate at one instant and the other half some time later. Matching them up and deciding when to act on a update would be tricky potentially error prone. Instead the two values are sent together in a single "complex" message containing two data points. Please note one known restriction: every message must contain ALL of the underlying data points.
Another example of a complex message is a message where one or more of the data points contains an array of values. Depending on the nature of the array, it may have an associated array of timestamps, a single timestamp, or a timestamp and interval.
Metadata
Metadata are properties of a data point that do not change. They are defined by each application using the data point and during the deployment phase, Unity Edge validates that each application has matching definitions for each data point. The fields are described in the Application Configuration Editor and REST documentation (Swagger). Upon system startup or deployment, Configuration Manager publishes the metadata for each data point on its associated _metadata. data point.
Metadata is published in a separate message from the value/quality/time message of a datapoint to avoid sending the unchanging metadata every time a data point updates.
The name of the metadata message is the same as the data point name with _metadata. appended
liveValue.postvalidConfig.this.<appName>.0.<topicName>._metadata.
With ZMQ, when you subscribe to a data point, you are also subscribed for the message containing the metadata of that data point. In the event of a metadata change (due to an application version upgrade for example), any applications consuming the data point will receive the change of metadata.
This allows software such as Unity Edge or an HMI to subscribe to sections of the hierarchy of data points and know how to render them based purely on the contents of the messages received on that subscription.
Data flow overview
Although SDK applications typically use the interfaces exposed via REST or other protocols, an overview showing how data flows internally between source and destination within the HCC2 may be useful. As mentioned above, this is done using ZMQ publish-subscribe connections. A central service for forwarding data from publishers to subscribers called the ZMQ proxy, ensures that every application using the internal message bus connects to a single service. This is what allows an application to be added to the system at any time without reconfiguring of how data flows, as all forwarding is done by the proxy based on the data point names that consumers are subscribed to.
Subscriptions
A subscription in ZMQ is a request to a publisher to provide any messages where their content matches a filter. A message passes the filter if every character of the filter string is at the start of the data point name. This means that if a subscription is set to the full name of a data point, it will receive only that data point (and its metadata).
It is also possible to set the subscription string to the first portion of a data point name which would result in receiving every message that starts with those characters.
It is not possible to filter on the individual "sub-topics" within a complex message. You must receive an entire message, and complex messages contain every data point defined for that message.
Using subscriptions effectively in the HCC2 enables efficient set up and reduced overhead when consuming multiple related data points
Configuration workflow
Configuring a workflow requires an application to process several steps. Upon startup, applications interact with the Configuration Manager service to define the data and configuration they interact with, and the screens which appear in the Unity Edge configuration software, and make themselves known to the rest of the system. This allows end users to configure and map data sources to consumers for all applications in Unity Edge configuration software.
Once an application is registered with Configuration Manager, it must wait for an initial configuration set to be deployed via Unity Edge. This enables Unity Edge and the Configuration Manager to validate that all of the applications have defined compatible inputs and outputs and are prepared to initiate communication with each other.
Once the Configuration Manager has the configuration to be deployed, it notifies each application waiting for configuration and provides their configuration files. Applications can then reject or accept and proceed with applying this initial configuration and start reading and writing data to the rest of the system.
Configuration manager
Configuration Manager is a central part of the workflow for any application participating in the registration process. In the case of the REST API, parts of this interaction are handled by REST server to reduce the complexity of the startup process.